
Claude Opus 4.6 — aktualizacja modelu Anthropic z naciskiem na kodowanie i dłuższe sesje. W komunikacie podkreślono, że model planuje uważniej i dłużej utrzymuje zadania agentowe. Zwraca się też uwagę na mocniejsze code review oraz debugowanie, czyli samokontrolę jakości. Mówiąc prościej, model częściej wyłapuje własne błędy, zanim zauważysz je Ty. Jest też pozycjonowany do zadań biurowych, informuje rapowo.pl.
„Doceniam, gdy model sam się zatrzymuje i prosi o sprawdzenie ryzyka” — komentuje team lead.
Kodowanie i review: więcej dyscypliny
Opus 4.6 jest opisywany jako model do zadań z kilkoma krokami i kontrolami. Szybciej przechodzi przez proste fragmenty i nie gubi wątku, gdy trzeba wrócić do bardziej złożonej części. W dużych repozytoriach zmniejsza to ryzyko „efektów ubocznych” zmian. Mniej drobnych poprawek po odpowiedzi — więcej czasu na decyzje. Szczególnie w długich sesjach.
Kontekst 1M i mniej „context rot”
Po raz pierwszy dla klasy Opus zadeklarowano okno kontekstu 1M tokenów. Komunikat mówi też o lepszym wyszukiwaniu informacji istotnych w dużych zbiorach dokumentów. Podkreśla się mniejszą degradację jakości w długich dialogach. Jako przykład podano MRCR v2 (8-needle, 1M): Opus 4.6 ma 76%, podczas gdy Sonnet 4.5 — 18,5%. Przedstawia się to jako dowód korzyści z długiego kontekstu.
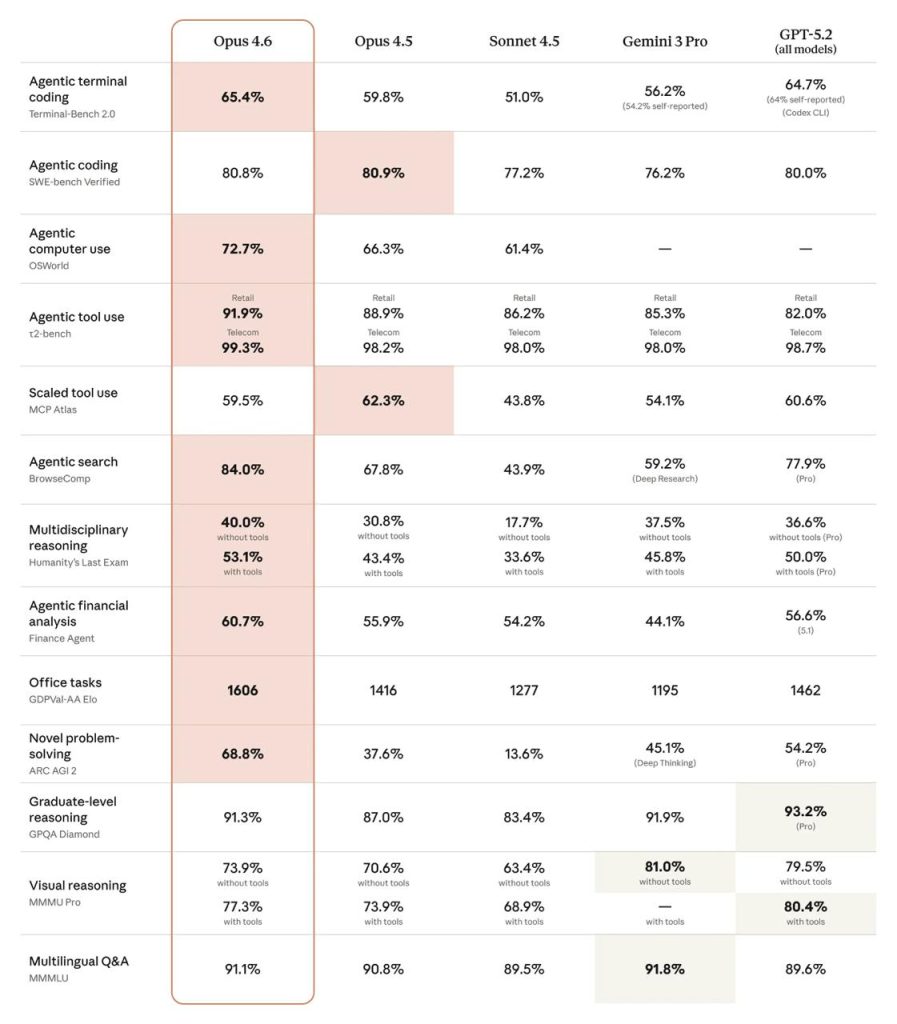
Benchmarki: kluczowe deklaracje
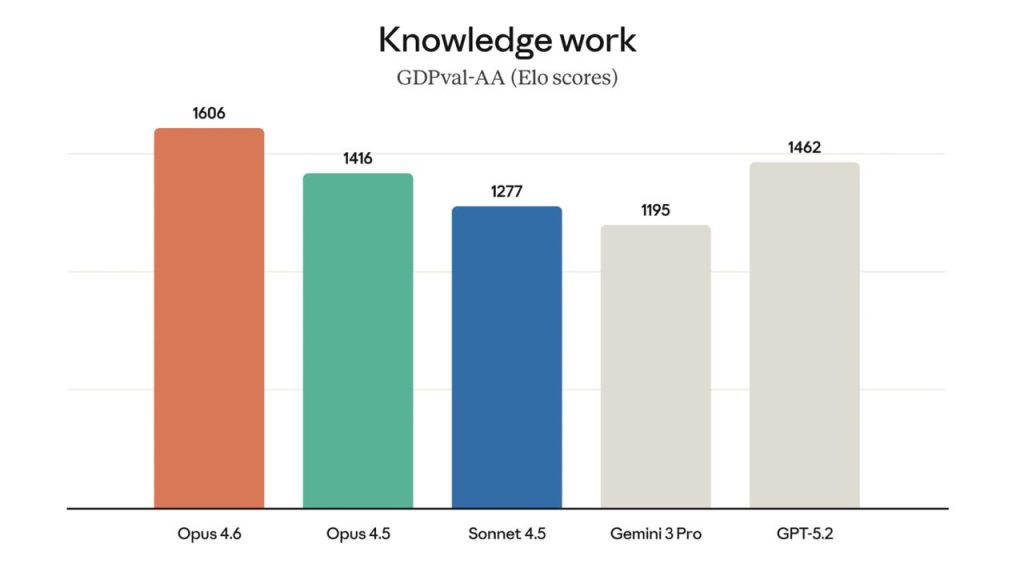
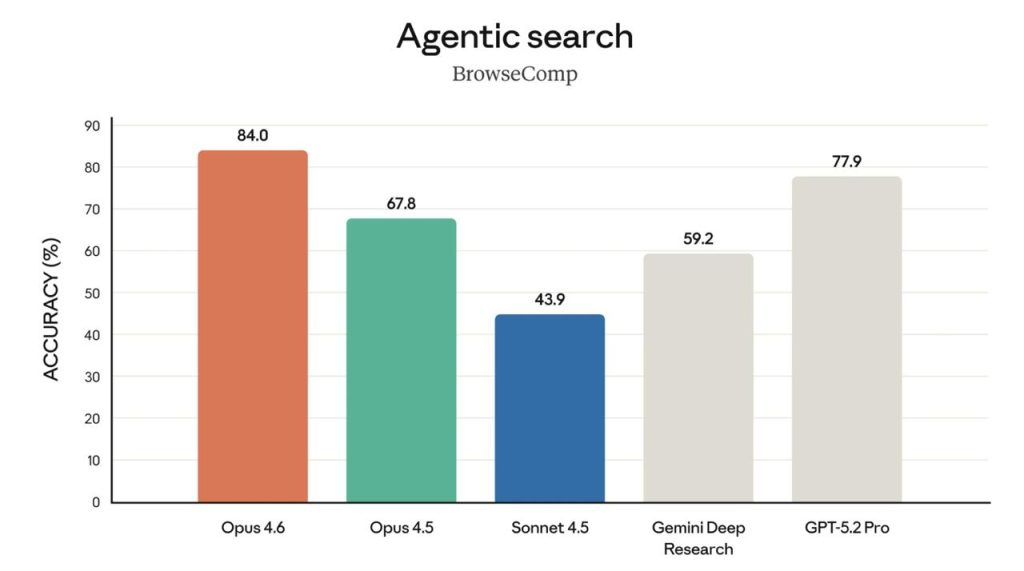
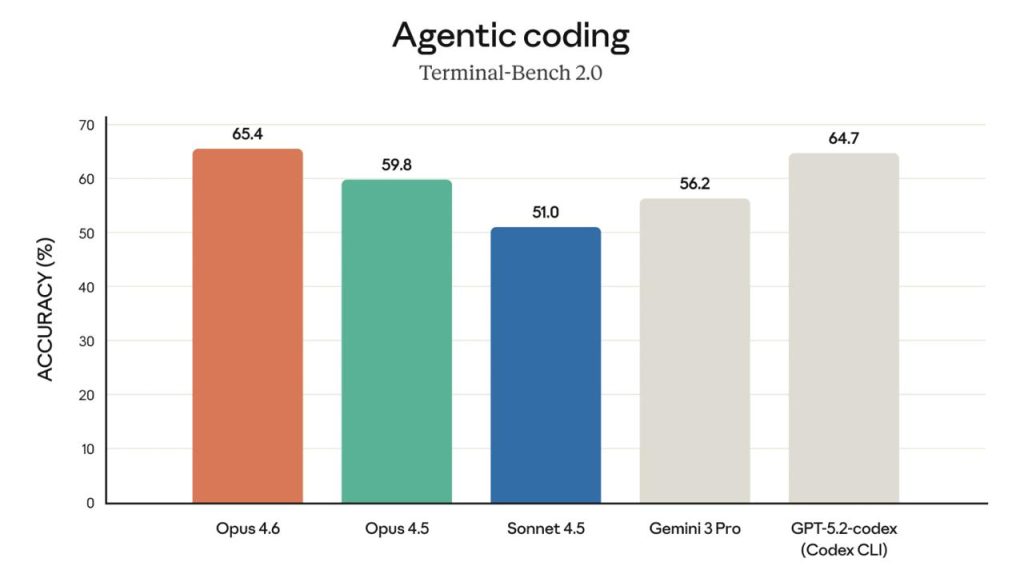
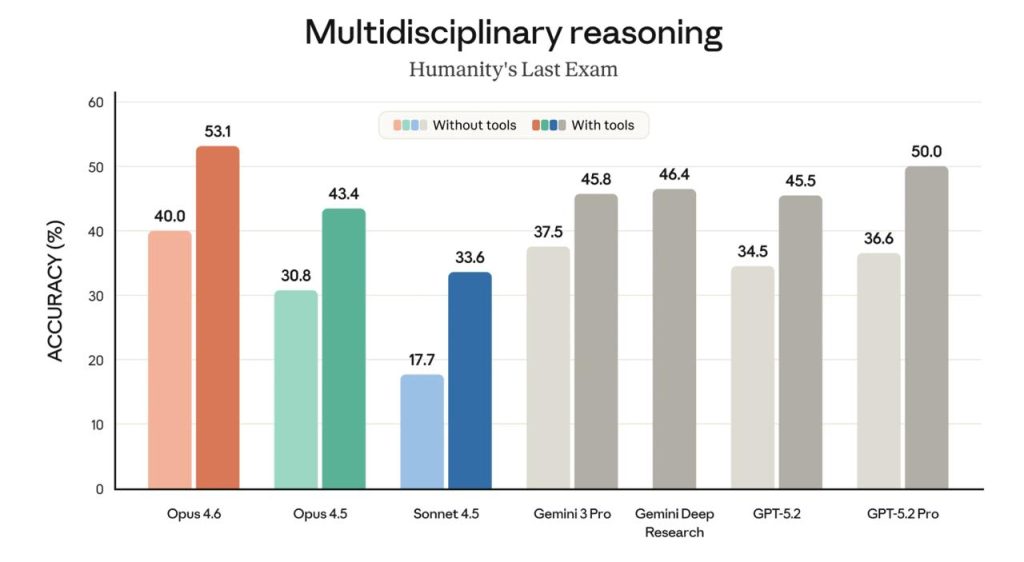
W materiale Opus 4.6 jest nazywany state-of-the-art. Wspomina się o najwyższym wyniku w Terminal-Bench 2.0 (agentic coding). Pisze się też o prowadzeniu w Humanity’s Last Exam. W GDPval-AA model — według deklaracji — wyprzedza OpenAI GPT-5.2 o około 144 Elo, a Opus 4.5 — o 190 Elo. Osobno wyróżnia się BrowseComp do wyszukiwania online.
| Test | Fokus | Deklaracja |
|---|---|---|
| Terminal-Bench 2.0 | agentic coding | top |
| Humanity’s Last Exam | rozumowanie | lider |
| GDPval-AA | praca wiedzy | +144 Elo |
| BrowseComp | wyszukiwanie | top |
Aktualizacje API: effort, compaction, adaptive thinking
W API dodano poziomy effort (low, medium, high, max) oraz parametr /effort. Ma to ograniczać „overthinking” tam, gdzie liczą się szybkość i cena. Opisano adaptive thinking, gdy model sam decyduje, czy potrzebne jest rozszerzone myślenie. Pojawił się też context compaction (beta): starszy kontekst jest podsumowywany, gdy rozmowa zbliża się do limitu. Dodatkowo zadeklarowano do 128k tokenów w odpowiedzi oraz ceny premium dla promptów powyżej 200k tokenów.
„Te ‘pokrętła’ dają kontrolę nad tempem, kosztem i jakością” — wyjaśnia architekt integracji.
Excel, PowerPoint i szybki test dopasowania
W komunikacie podkreślono, że model nadaje się do badań, analiz finansowych i pracy z dokumentami. Zapowiedziano aktualizacje Claude w Excelu oraz uruchomienie Claude w PowerPoincie w trybie preview dla planów Max, Team i Enterprise. Pojawiają się też agent teams w Claude Code (research preview), gdzie kilka agentów działa równolegle. Przed testami warto porównać swój scenariusz z typowymi przypadkami użycia. Poniżej krótka checklista, która pomaga szybko się zorientować.
- Długie zadania agentowe z kilkoma iteracjami poprawek.
- Duże dokumenty i potrzeba stabilnego wyciągania szczegółów.
- Krytyczne review, debugowanie i samokontrola błędów.
- Automatyzacja w Excelu i prezentacje w PowerPoincie na danych.